01
Deploy at the edge
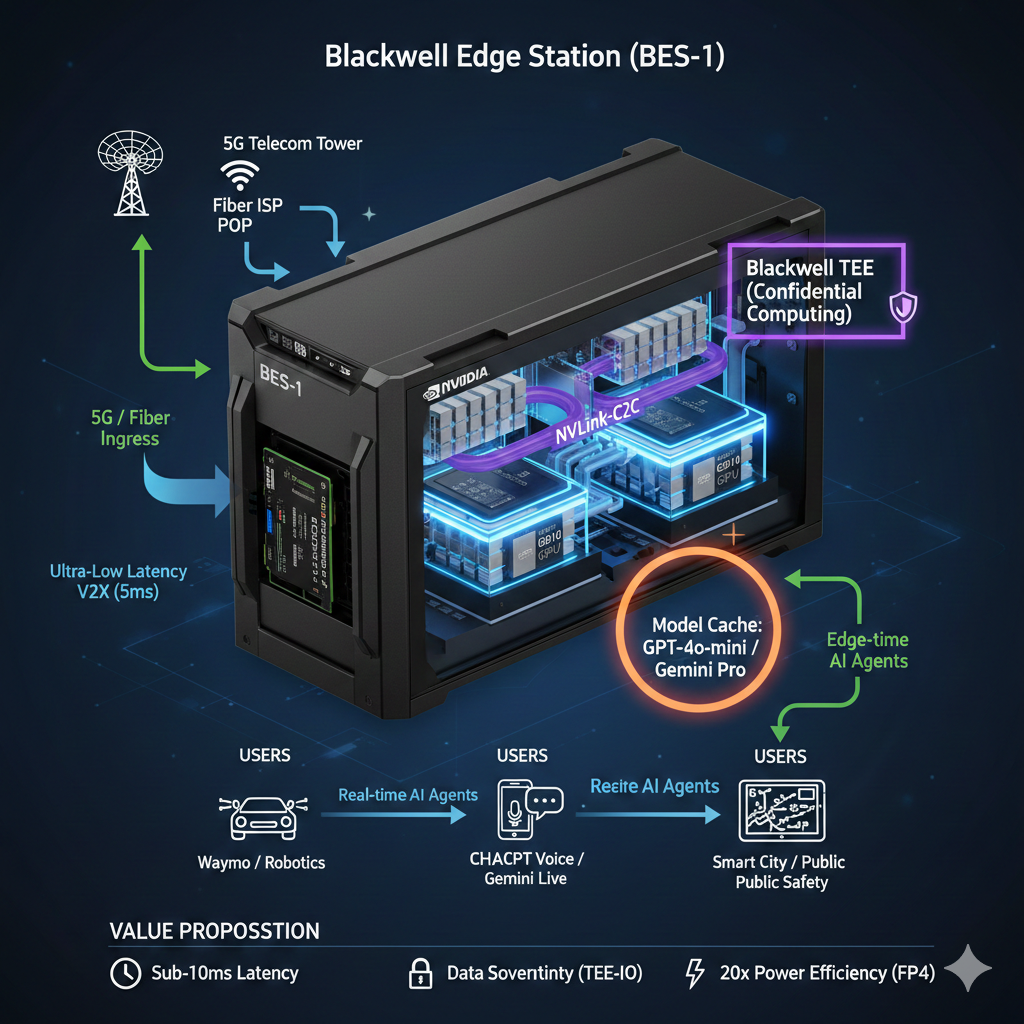
We are industrializing the Blackwell architecture for telecom environments. Stations near users—at carrier POPs or tower-adjacent sites—so inference happens locally.
Edge inference for voice, vision, and LLMs
SwiftInference deploys multi-tenant edge stations at carrier and tower sites to cut latency, reduce bandwidth, and deliver predictable inference economics.
Drop-in edge inference that behaves like cloud: auth, routing, quotas, SLAs, and observability.
We are industrializing the Blackwell architecture for telecom environments. Stations near users—at carrier POPs or tower-adjacent sites—so inference happens locally.
Two reserved slots provide predictable performance. A third optional spot slot absorbs bursty workloads.
SwiftFabric routes each request to the best node based on health, load, latency, and policy—then streams results.
Secure boot, attestation, signed updates, and per-tenant isolation guard workloads and infrastructure.
Real-time AI inference for LLM workloads, voice and video with predictable latency.
Serve token streams closer to users. Run embeddings on spot capacity and keep the main model pinned.
Low-latency STT/TTS and conversational agents near users. Protects jitter and improves turn-taking.
Reduce backhaul by processing video locally: object detection, safety, retail analytics, and industrial monitoring.
Monetize tower and POP real estate with reserved + spot inference capacity, SLA reporting, and data-sovereignty deals.
Own your inference like a CDN: distributed edge POPs, predictable cost, tighter p99, and enterprise-friendly data locality.
SDK/API edge inference: near-device latency without shipping huge models, with streaming output and predictable plans.
Best-effort capacity
Secondary slot
Primary slot + enterprise
Pricing shown is illustrative for early deployments. Final pricing depends on site density, workload characteristics, and SLA terms.
Answers to the questions buyers frequently ask.
Two customers get guaranteed slots. A third optional spot slot is interruptible. We don’t oversell beyond that because tail latency matters.
No. We focus on the platform: routing, slot enforcement, observability, and secure operations. We deploy on best-fit edge systems for the site class.
Secure boot, signed updates, and node attestation are required before workloads run. Models can be encrypted at rest with keys released only to trusted nodes.
Pick one metro area and 20–50 edge sites (carrier POPs or tower-adjacent). We deploy, integrate your runtime, and tune for your p95/p99 targets.
Tell us your workload (voice, vision, LLM), target metros, and SLA requirements. We’ll respond with a deployment plan, slot sizing, and pricing.